
By Trey Plante ‘24, Dale Ross ‘22
Our goal was to develop a dataset of Snapchat ads to enable the Wesleyan Media Project to research an area of ads that impacts a younger demographic, and hasn’t been explored as thoroughly as other platforms like Facebook. The Snapchat political ads library offers an interesting look into how political ads operate on primarily video based platform that has unique user base. By investigating the Snapchat political ad library, we hope to recognize differences between ads on different platforms, and discover underlying trends in political entities behavior across platforms. We extracted text from the speech in ad videos and text in ad images and generated facial recognition results from the Snapchat 2020 political ad dataset. Additionally, we developed a classifier that predicts the party lean of a Snapchat ad using the content data we gathered. As a result of our research, we have made it possible for the Wesleyan Media Project to analyze Snapchat ads, and have taken steps to predict the party of future Snapchat ads.
Data
Our initial data was Snapchat advertisement data gathered from the general election in 2020. We downloaded our data straight from Snapchat’s political ads library. The initial dataset was 12733 advertisements. Each entry contains the url of the advertisement, including classifications including, Spend, Impressions, StartDate, EndDate, OrganizationName, BillingAddress, CandidateBallotInformation, PayingAdvertiserName, Gender, AgeBracket, CountryCode, and Regions. For our tasks, we were mostly concerned with the url, which contained content of the advertisement–as one or more images or videos.
We had to do quite a bit of data management in order to generate the files to use for image and video facial recognition and transcription. Firstly, we had to gather and download the files. We ran a python script on the Wesleyan Media Project server to scrape all of the urls and download the associated image(s) or video(s) from them. Once we had these images and videos, we uploaded them to the Wesleyan Media Project AWS s3 bucket. We then ran AWS video recognition, AWS image facial recognition and transcription, and Google ASR video transcription on our files (more on this in methods). The output of these files we merged into our master file, for use on our classifier and for use by the Wesleyan Media Project.
We also used data from the Wesleyan Media Project Facebook entities files to generate training data for our classifier. This file contains data on a set of recognized political advertising entities. It includes hand coded data, most notably their party affiliation (party_all), which we used as training data for our classifier. We merged in the entities using jaccard similarity (more on this in methods).
Methods
To generate data about political ads on Snapchat, we processed the videos and images we scraped using computer vision and natural language processing techniques. Firstly, we wanted to garner information about the content of the ads, namely the people who appear in the ad and the message of the ad. With AWS Rekognition, we were able to process all the videos and images to find any text and prominent politician that appeared in the ad. Using Rekognition’s image model, we indexed and converted all of the faces we wanted to recognize into matrices, then, by passing the ad images into Rekognition’s neural network, we searched each image for a face and stored the ad id and person if there was a match. After facial recognition completed, we used AWS Textract to efficiently run optical character recognition on each ad image, and stored the resulting text. Because processing videos is more computationally expensive, we broke the videos into batches of 20 and ran facial recognition on each batch of videos, searching for faces in each frame of the video Amazon’s using neural networks. Finally, using Google’s automatic speech recognition, we transcribed and extracted the speech from each ad video. With our new Snapchat metadata we hope to enable Wesleyan Media Project to perform content analysis on the Snapchat dataset and use the extracted text to predict the party lean of Snapchat ads.
Equipped with the predictive information for our training data, we needed to develop ground truth for our samples so that we could actually train our classification model. Specifically, we needed to identify the party lean of a subset of our ads so that our model can learn what content indicates an ad is Democratic or Republican. To find out what party an ad was associated with we performed a keyword search and utilized MinHash to match Snapchat entities to our Facebook entities for which we already know the party. We first searched through the entity tags of the Snapchat entities and marked them as Democratic leaning if they contained the keyword “Biden” or “Democrat” or Republican leaning if they contained the keyword “Trump” or “Republican”. After receiving 160 matches from the keyword search, we read through the entities associated with the matches and ensured that they appeared correct; they didn’t say something like “Unite Against Biden”.
Next, we performed MinHash to compare all of the Snapchat entities to all of Wesleyan Media Projects’ known Facebook entities. MinHash, or min-wise independent permutation locality-sensitive hashing scheme, is a data mining technique to determine the similarity between sets of arbitrary size. MinHash works by transforming each tokenized string into a set of unique integers, and computing the Jaccard Similarity, the size of the intersection, with another set of integers. We computed the MinHash value of every Snapchat entity tagline compared to every Facebook entity tagline, and considered a pair of entities a match if the value was at least .75, on a scale of 0 to 1. The whole process ended up giving us 6,600 matches, meaning we had 6.6k ads for which we knew the party. Due to the transcription results, we only had 1,500 ads for which we knew the party and we had content results for, giving our training set a size of 1.5k. While our training set was fairly large, it also happened to be very imbalanced; 4 times as many ads in our training set were labeled as Democrat compared to Republican. However, we think this is largely due to the composition of Snapchat ads being mainly Democratic because of younger demographics on the app, indicating that our test set is representative of the larger population of ads.
Once we had our training data with party_all labels, we were able to generate our classifier. We used logistic regression on our advertisement text using the scikit package with python in order to predict the party lean of political advertisements. We vectorized the texts to build our regression model using CountVectorizer, which turns a collection of text documents into numerical feature vectors. Then, we converted these feature vectors into a feature matrix for our logistic regression model to run using TfidfTransformer, which transforms the feature vectors by term-frequency multiplied by inverse document-frequency. We generated our model using logistic regression with newton-cg as our solver. Logistic regression uses gradient descent, which is a method of approximating a local minima in order to minimize a loss function. Newton cg uses quadratic function minimisation which takes first and second partial derivatives when computing gradient descent. We split our data into a validation and training set on a 0.3/0.7 split, respectively. This resulted in a validation set of 469 advertisements. We fit the model on our training data and computed accuracy on our test data.
Results
Our classifier performed well against our validation set. While this is a small sample of our data, the results are promising for the effectiveness of classifying the political lean of Snapchat political advertisements. Using just the transcribed text of the advertisements, we were able to correctly predict ad lean of 95% of the advertisements.
Figure 1: Accuracy score of our Snapchat Classifier on our Validation Data Set
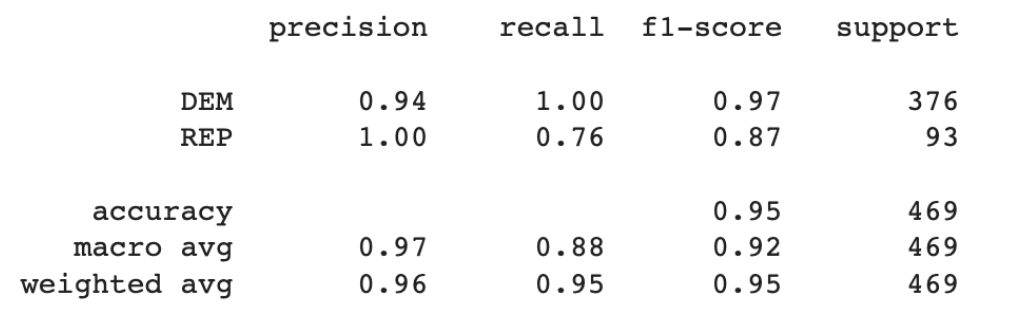
Figure 1 displays the results of our classifier on the validation data. Our classifier is especially good at predicting democratic advertisements, with precision of .94 and recall of 1. This means that every single democratic advertisement was correctly classified as Democrat. Our classifier was less effective on Republican advertisements, with precision of 1 and recall of .76. This means that 24% of Republican advertisements were classified as Democrat. The weighted accuracy was .96 and .95 respectively. This is quite good and much better than randomly assigning ads based on the distribution of advertisements, which would generate and accuracy of around .8.
Figure 2: Confusion Matrix of our Snapchat Classifier on our Validation Data Set
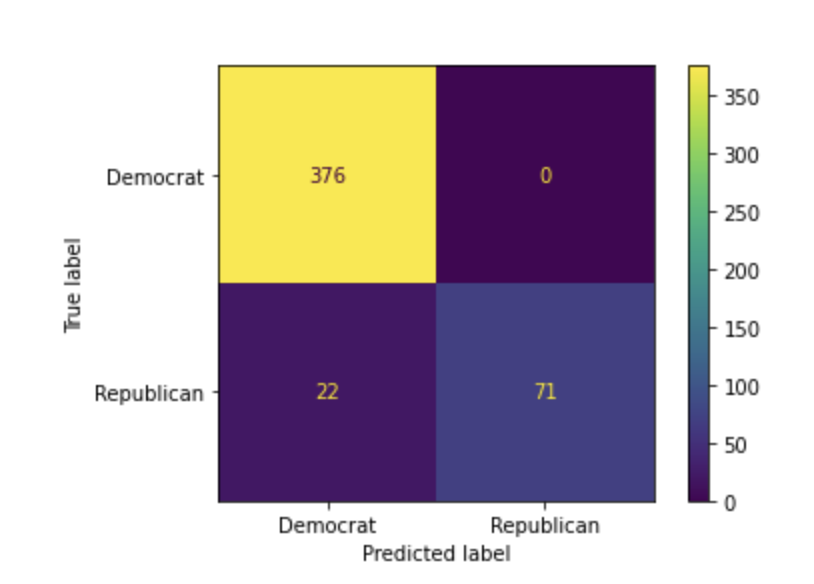
Figure 2 shows a confusion matrix of the classifier on the validation set. This confusion matrix displays the correct predictions, as well as the false classifications for Democrat and Republican. Figure 2 illustrates the imbalance with our data, and how it could have affected our results. With a full training set of just over 1563, and a training partition of just over 1000, our training data is small. With so little Republican data especially, our model could have struggled to effectively generate a vectorized feature matrix that accurately describes our data.
Conclusion
Through our analysis, we have generated a dataset of 12,733 ads from Snapchat for which we have content and party information. With this dataset, the Wesleyan Media Project can perform various types of analysis on the Snapchat dataset, such as textual content analysis and political candidate research with recognized faces. While we did a lot this semester, we have a lot of loose ends that we would like to tie up this summer. In particular, we would like to refine and improve our classifier. We lack a large training set, and we could improve our methods for connecting the set to the Facebook entities file. However, it would be difficult to see too much improvement on this front, since we have already connected a large number of unique ads to entities. One thing we could to improve the quality of our training set is to integrate other years into our classifier. We would have to scrape those years’ datasets for the files and rerun image and video facial recognition and jaccard similarity on them, but hopefully it would improve the accuracy of our classifier. Snapchat has advertisement data in its political advertisement library from 2018 to 2022, so we could theoretically quintuple our dataset for the classifier. Also, refining the specifics of our logistic regression model by testing different methods of transforming the advertisement text and playing with solvers could also help improve the effectiveness of our classifier.