
by Inesh Vytheswaran ’25
The topic of this research is the Wesleyan Media Project’s hand-coding of issues. It is important that WMP’s hand-coding is accurate since much of our classification and analysis depends on it. In order to analyze WMP’s hand-coding, we explored discrepancies to the issue coding of Kantar, the underlying data provider. WMP and Kantar do not have identical coding criteria, so some differences are to be expected. However, using Kantar’s tagging allows us to expand our dataset and comparing them could provide valuable insights.
Data
The data used comes from both WMP and Kantar. The hand-coding comes from WMP’s research assistants who watch the ads and hand-label them when the ad is related to an issue. Ads were only compared if both WMP and Kantar had a similar issue tag. This amounted to 10,509 television ads classified for 40 WMP issue categories. These ads were aired in 2019 and 2020.
Methods
In this research, I experiment with a number of text-based methods to detect when an ad mentions an issue. The goal is to supplement WMP’s hand-coding, potentially improving it when compared to Kantar. The precision (a metric that aims to minimize false positives, ranging from 0 to 1, where 1 is best) and recall (false negatives) of Wesleyan Media Project’s hand coding was assessed when considering Kantar’s coding as the ground truth.
Results
The first method (which I refer to as ‘issue word method’) is based on the name of the issue category. If the transcript contained the issue name (or if WMP already coded it as a positive), the ad was classified as a positive for that issue. For example, if the transcript contained the word “budget” it would be classified as a positive in the text coding for issue budget. Table 1 shows the improvement from this initial approach. Because we only selected on word, this method only had a small effect on precision and recall.
Table 1: Text Coding with Issue Word
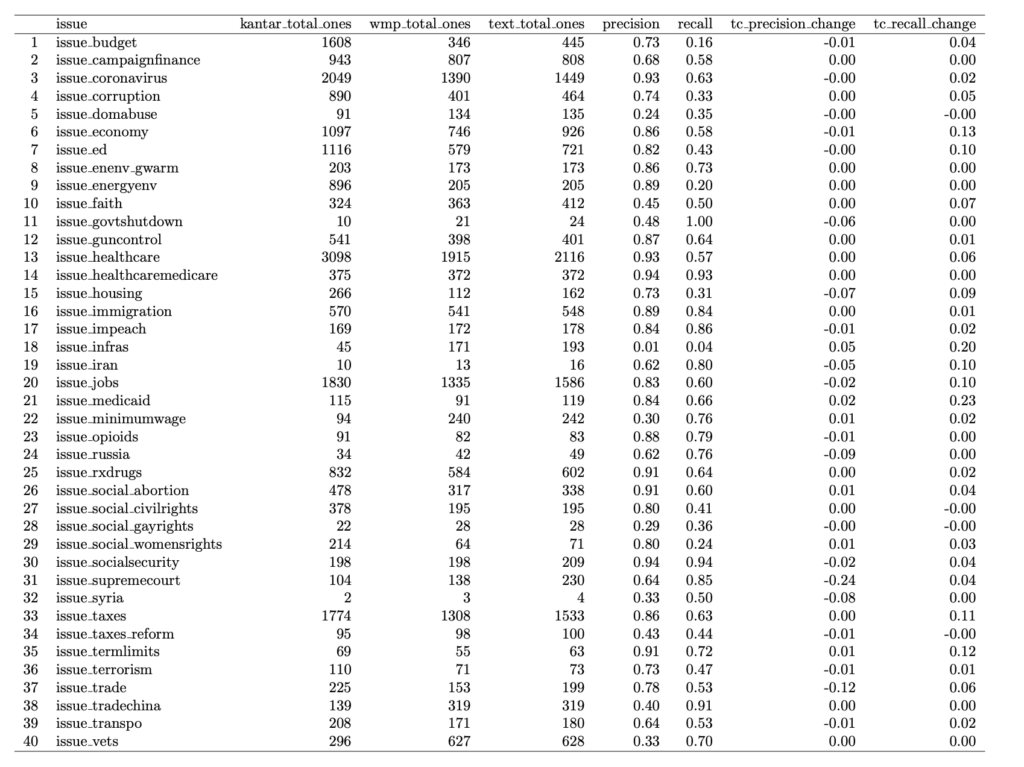
Table 2 is a text coding method I created based on word scores for each word that appears in the transcript. First, stop words were eliminated. These are words like “a,” “the,” “is,” and “are” which provide no analytical value. Next, to prevent the algorithm from scoring political buzz words the highest, words had to be penalized for appearing in non-issue-related ads. This was done by subtracting one from a numerical word score for each occurrence of this. When a word appeared in an ad coded by WMP or Kantar, the word score added was the fraction of ads coded as positive for the issue inversed and divided by two. Finally, the three words with the highest word score were selected. If the transcripts contained one of these words, or if WMP coded as a positive, the text coding column was coded as a positive. In the last two columns, the change in precision and recall of the text coding was found when once again considering Kantar as a ground truth.
Table 2: Text Coding with Word Scores
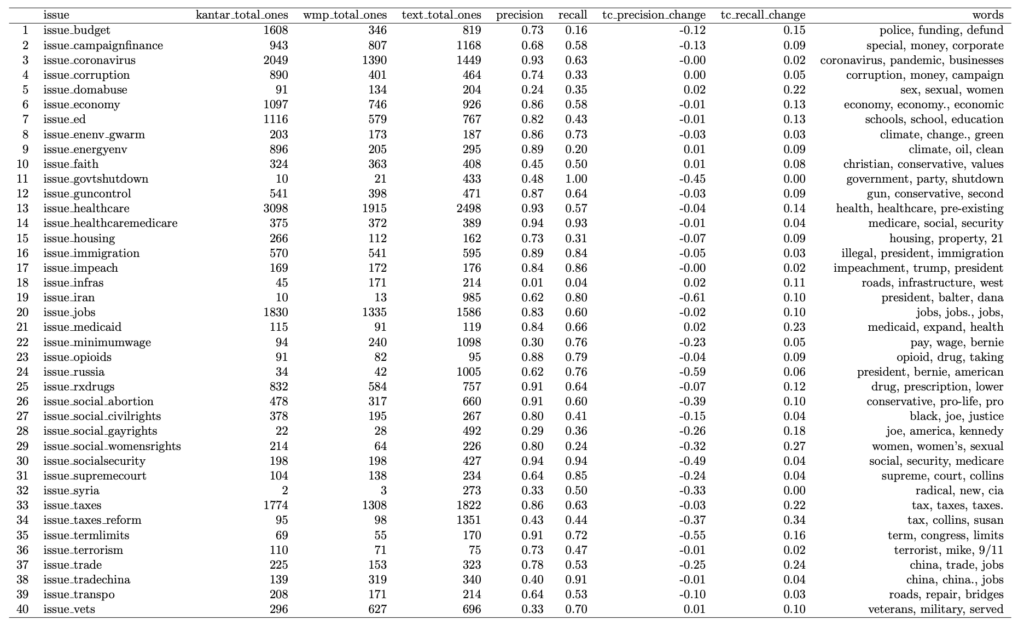
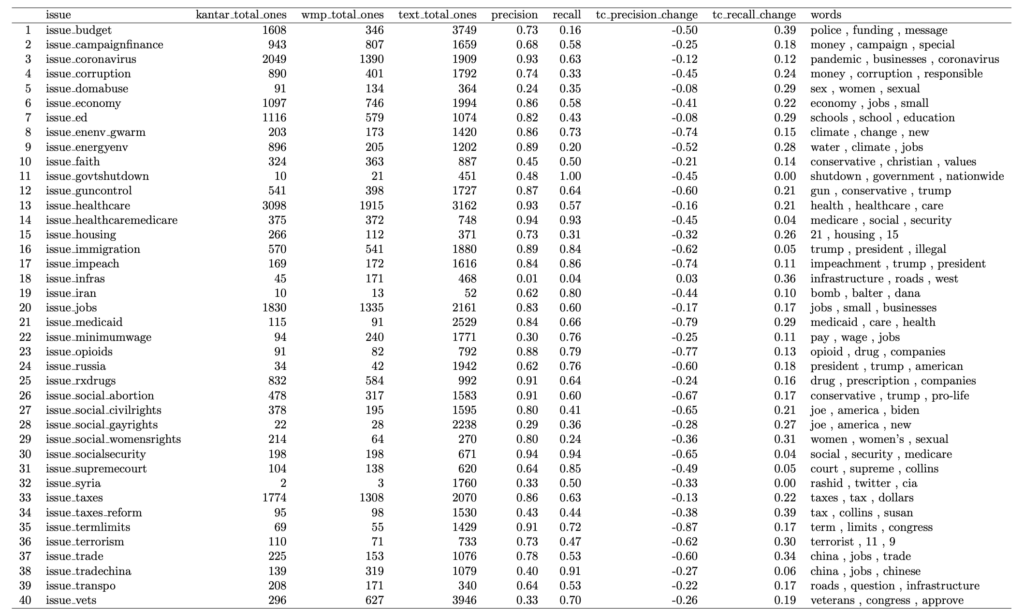
Table 3 utilizes the Dirichlet method from Monroe et al. (2008). This method is an approach to estimate term frequencies by incorporating a background language model, representing the global term distribution. The tf-idf (term frequency-inverse document frequency) method (Table 4) is a numerical representation technique that assigns weights to words in a document based on their frequency in the document and rarity across the entire document collection. Although the Dirichlet and tf-idf and methods are not great at improving accuracy, the word list provides valuable information relating to the issues.
Table 3: Text Coding with Dirichlet Method
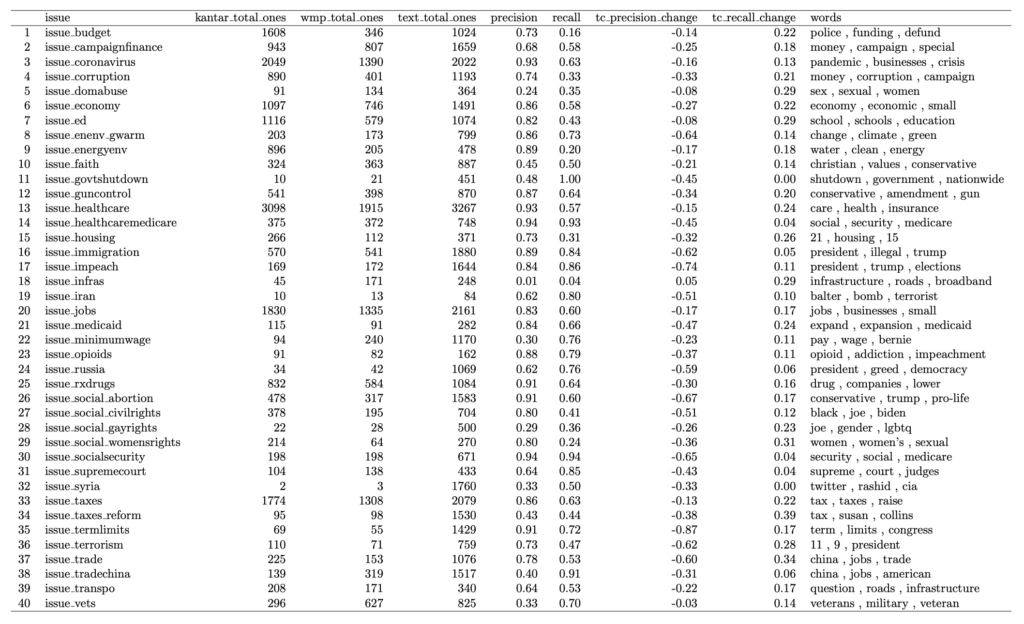
Table 4: Text Coding with TF-IDF Method
Conclusion
From this project, I found that it is extremely difficult to consistently improve accuracy based on selected words. The Dirichlet Method and TD-IDF methods are very efficient in improving recall but they come at high costs to the precision. By contrast, the issue word method only led to minimal changes. Therefore, the word scores approach tended to be the best method.
The text coding was able to improve performance for some issues. I considered the method effective if it increased recall by 0.1 without the precision decreasing more than 0.05. The issue word method was most effective for these issues: education, economy, infrastructure, jobs, medicaid, and term limits. The word score method was effective for the issues of education, domestic abuse, economy, infrastructure, jobs, and medicaid. The Dirichlet and tf-idf methods were only effective for the issue infrastructure. It is also worth noting WMP coded some issues such as budget and education a lot less frequently than Kantar, so improving recall was much easier than for other issues.
A more comprehensive approach would be to consider the entire transcript as a group of words and then create a scoring system for each of these groups. Although this text-coding method is far from ideal, it could be used to improve hand-coding for certain issues. Furthermore, examining the word lists created from the word score, Dirichlet, and tf-idf methods could provide valuable information on the most “issue-related” words.
References
Monroe, B., Colaresi, M., & Quinn, K. (2008) Fightin’ Words: Lexical Feature Selection and Evaluation for Identifying the Content of Political Conflict.
This material is based upon work supported in part by the National Science Foundation under Grant Number 2235006. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the author(s) and do not necessarily reflect the views of the National Science Foundation.