
By Sam Feuer ’23, Angela Loyola ’21, and Natchanok Wandee ’23
According to the New York Times, the Black Lives Matter (BLM) movement may be the largest movement in U.S. history. With fifteen to twenty-six million people protesting across the country after the murder of George Floyd, the quantity of people and their geographic spread has made it clear that racial justice is a very present issue for many Americans.
Protests and demonstrations are an essential part of the democratic process and can have a great impact on candidates’ platforms. Additionally, the ways that candidates frame the movement, either positively or negatively, can shape its future. Due to the prevalence of the movement, we were interested in researching how the movement has influenced presidential and senatorial campaigns. Conversely, we are also interested in how candidates talk about BLM, as they may provide some clues about the future of the movement. According to the Wesleyan Media Project, over $60 million has been spent on pro-Biden or pro-Trump Facebook ads alone between April 9th to August 8th. How prominent is the Black Lives Matter movement in these ads? How big of an influence has the movement had on these campaigns?
To evaluate this, we analyzed the frequency, content and spend percentages of the ads related to Black Lives Matter. Data used in this analysis came directly from the Wesleyan Media Project, which tracks advertising through Facebook’s Ad Library API tool.
APPROACH
Our original goal was to classify the superset of Facebook ads run between May 25th (the day of George Floyd’s murder) and July 25th into those related to Black Lives Matter and those not related. At this point, we should clarify what we mean by “Black Lives Matter related.” We count ads that either explicitly mention the Black Lives Matter movement (or key figures related to the movement) or pertain to issues being discussed as a result of the movement (e.g., police brutality, funding for police departments, political responses, etc.).
At first, we attempted to do this by matching keywords in each of the ad’s texts. The list of keywords we selected include: protest(|s|ing|ers|er), Black Lives Matter, police, George Floyd, riot, Breonna Taylor, (all|blue) lives matter, loot(ers|ings), rubber bullets, Ahmaud Arbery, rac(ist|ism|ial), law enforcement, systemic, tear gas, curfew, brutality, and excessive force. The parentheses indicate that the keyword could have any of the options separated by the vertical bars.
Figure 1 – BLM Keywords*
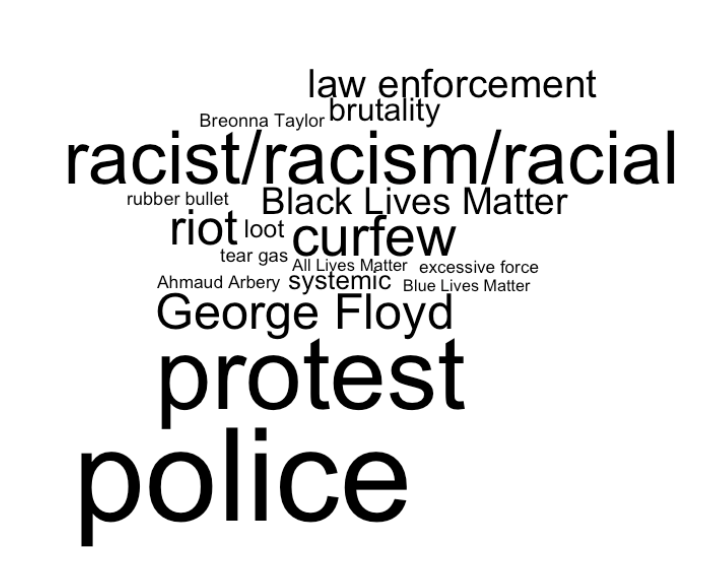
*The keywords used to search for BLM-related ads in the ad supersets, with size correlating to their frequency. This was done in June, so the keywords may be outdated.
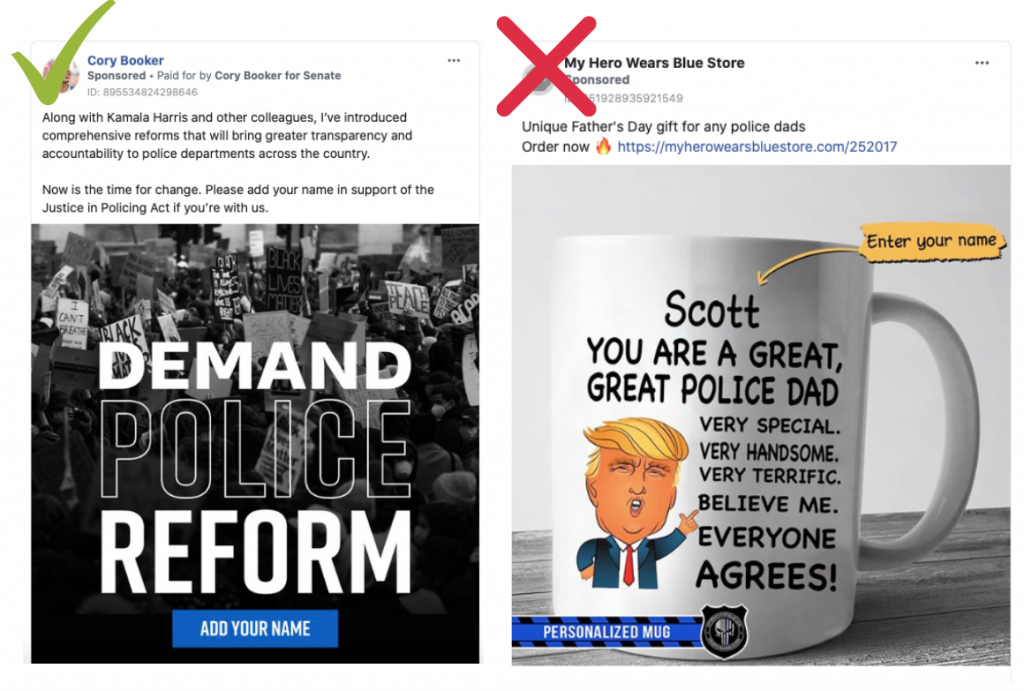
If one of these keywords was found in the text of the ad, then it was classified as Black Lives Matter related. However, this quickly proved to be ineffective because many terms used in racial justice related ads are also used in ads that are unrelated, such as “police,” “protest,” and “law enforcement.” For example, the keyword police appeared in both the ads highlighted in Figure 1, but only the ad on the left was Black Lives Matter related.
Figure 2 – Two ads which use the keyword “police,” one related to BLM (left) and one unrelated (right)
Therefore, to identify BLM-related ads more accurately, we decided to narrow our focus to presidential and senatorial ads and explore two possible solutions: manual coding and topic modeling.
PRESIDENTIAL RACE
Each Facebook ad has a unique ID, but it is common for ads with different IDs to have the same text. This is especially common among Biden and Trump’s ads. Since the majority of ads had duplicate text bodies (we did not focus on images), there was a relatively small quantity of unique presidential ad texts, so we were able to hand code these ads based on the conceptual definition above.
Table 1 – BLM-Related Presidential Ads
Figure 3 – Presidential Candidates’ Total Ad Spends on BLM-Related and All Ads
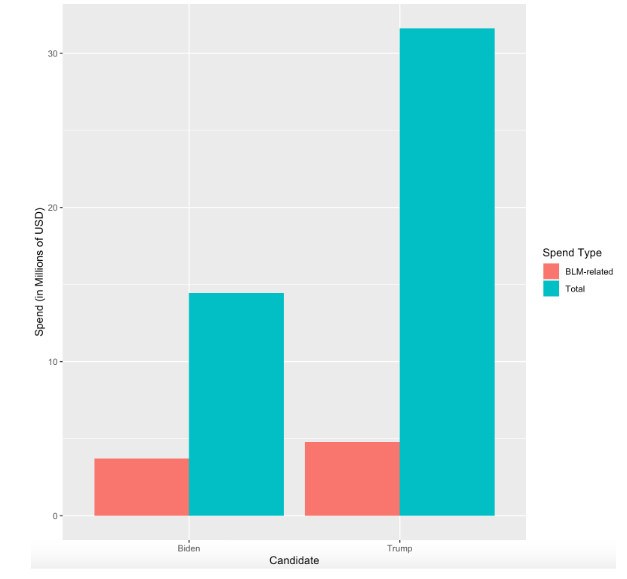
The data indicates that Biden spent about $3.7 million on BLM-related ads, while Trump spent about $4.7 million. However, because Trump spends much more on Facebook ads in general, a smaller percentage of his spend is on ads pertinent to the movement (about 15% compared to Biden’s 25%). Biden also has a small amount of unique text bodies, each of which he spends a lot on, which contrasts Trump’s large number of slightly differing text bodies with lower spend values.
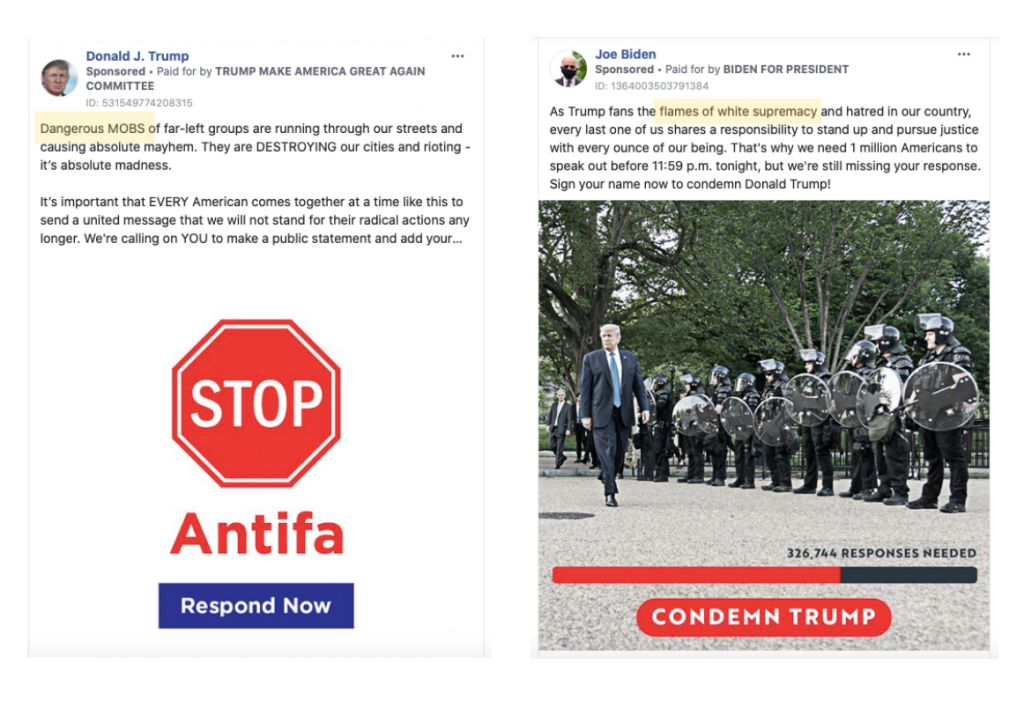
It is also important to note that while these numbers may indicate how much attention was devoted to issues related to the Black Lives Matter movement, they do not show the different ways in which the candidates talked about the movement. For example, as shown in Figure 3, many of Trump’s ads call the protesters “rioters” and “anarchists,” whereas Biden’s reference Trump “fanning the flames of white supremacy.”
Figure 4 – Examples of Biden and Trump BLM-Related Ads
SENATE RACES
Since the Senate races have many more candidates, there were many more unique ad texts. This made the hand coding approach unfeasible. Therefore, in order to identify relevant ads for analysis we decided to try topic modeling. Topic modeling is the use of statistical models to find “topics” that exist in a collection of documents through identifying different patterns and groups of keywords within them. While keywords may exist in multiple topics, the possibilities of them occurring is different for each one. When the model is run through a data set, each ad is assigned a “score” for each topic that indicates how likely that ad is to fall under it. We first ran the mallet topic modeling package on the entire senatorial ad set using 60 topics that gives a reasonable fine-grained result. This yielded two topics that were the most relevant to Black Lives Matter, including words like “Police”, “Justice”, and “Mob”. In order to capture senatorial ads that mention Black Lives Matter across regions in both parties, we subsetted the model by party (Democrat and Republican). Our results are shown in Figure 5.
Figure 5 – Top Words in the BLM-Related Topics from the Topic Model, Separated by Party
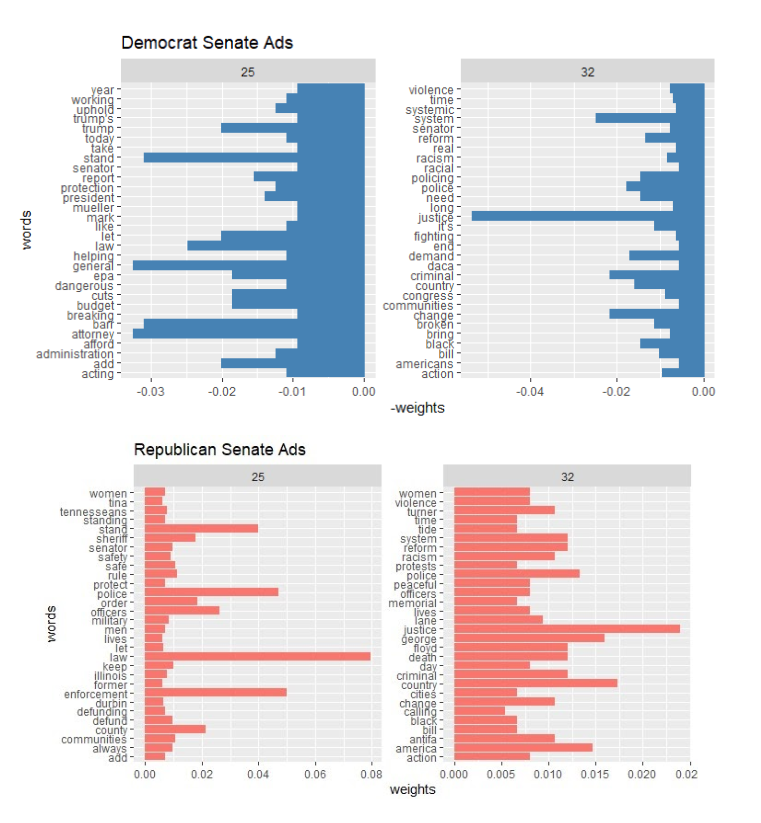
Our results indicate that there is a difference in the way that Black Lives Matter is discussed across parties. As seen in topic 32, Democrats tend to engage with the issue using words that address systemic racism, such as “reform” and “justice”. Conversely, among Repbulican candidates, topic 35 indicates a higher weight on words that support law enforcement, such as “safety” and “order”.
However, in the end, using topic modelling to classify ads that were related to Black Lives Matter did not work as accurately as we needed. While the model was able to capture many ads that were related, it also classified many ads incorrectly by showing a high score when the ad was not related at all. We speculate that many characteristics of the data that had previously given us trouble when researching the presidential race (racial justice terms being used by unrelated ads) are to blame.
DISCUSSION AND NEXT STEPS
There were multiple other models we tried using to classify the ads after the keyword search. In order to decide where to go from here, we decided to reflect on these methods and analyze why they failed. Our first attempt was with the Naive Bayes model. This type of model uses a training set of ads that are hand coded. The computer then calculates the probabilities of each word being in a BLM related ad and in a non-BLM related ad and uses these to classify the whole set of ads. The next model we tried was Random Forest. This model uses a hand coded training set of ads to create many “decision trees,” which classify ads based on the words they use. Our last attempt was using the LDA topic model in the Mallet package. This model provided interesting results, although it is not the best for classifying the ads because it is “unsupervised,” which means it doesn’t use a manually coded “training set.” It is better for identifying features of the text rather than sorting based on a topic of interest.
We realized that these approaches failed due to certain characteristics of the data. The BLM-related ads make up a relatively small portion of the total set. This problem of “imbalanced classes” is a common issue when using machine learning methods because it makes it difficult for the model to differentiate between classes. Additionally, many ads only briefly mention the movement, and the models were further thrown off by ads selling police-themed merchandise. Finally, the ways that politicians frame the protests are extremely varied; some frame them violently, focusing on attacks on people and property, while others frame them non-violently, focusing on the transformative power of the protests.
We began thinking how we could use the parts that did work from each attempt to build on our research. In the future, we hope to build a “confidence score” function which combines all of the previous models results to build a more accurate prediction for each ad. This function would use a point-based system to award a score to each ad. A higher score would mean it is more likely to be Black Lives Matter related. For example, an ad would receive a point for containing a keyword, then it would receive another point for each model that positively coded it. Finally, we would determine a threshold by which we could indicate that all ads above that score are positive.
By doing this, we hope to eliminate the need for hand coding ads in the future, at least for the senatorial ads. This method would allow us to confidently identify relevant ads and analyze the ways that candidates talk about Black Lives Matter movement, and how demographic factors— such as gender, party, and state—affected the ways that candidates talk about the movement.
Authors: Sam Feuer ’23, Angela Loyola ’21, and Natchanok Wandee ’23
Contributors: Natalie Appel ’23, Brianna Mebane ’22, Kevin McMorrow ’20, and Conner Sexton ’20